Prompt-and-Rerank: A Method for Zero-Shot and Few-Shot Arbitrary Textual Style Transfer with Small Language Models
Abstract
We propose a method for arbitrary textual style transfer (TST)-—the task of transforming a text into any given style--utilizing general-purpose pre-trained language models. Our method, Prompt-and-Rerank, is based on a mathematical formulation of the TST task, decomposing it into three constituent components: textual similarity, target style strength, and fluency. Specifically, our method first uses zero-shot or few-shot prompting to obtain a set of candidate generations in the target style, and then re-ranks these candidates according to a combination of the three components above. Empirically, our method enables small pre-trained language models to perform on par with state-of-the-art large-scale models while consuming two orders of magnitude less compute and memory. Finally, we conduct a systematic investigation of the effect of model size and prompt design (e.g., prompt paraphrasing and delimiter-pair choice) on style transfer quality across seven diverse textual style transfer datasets.
Prompt-and-Rerank
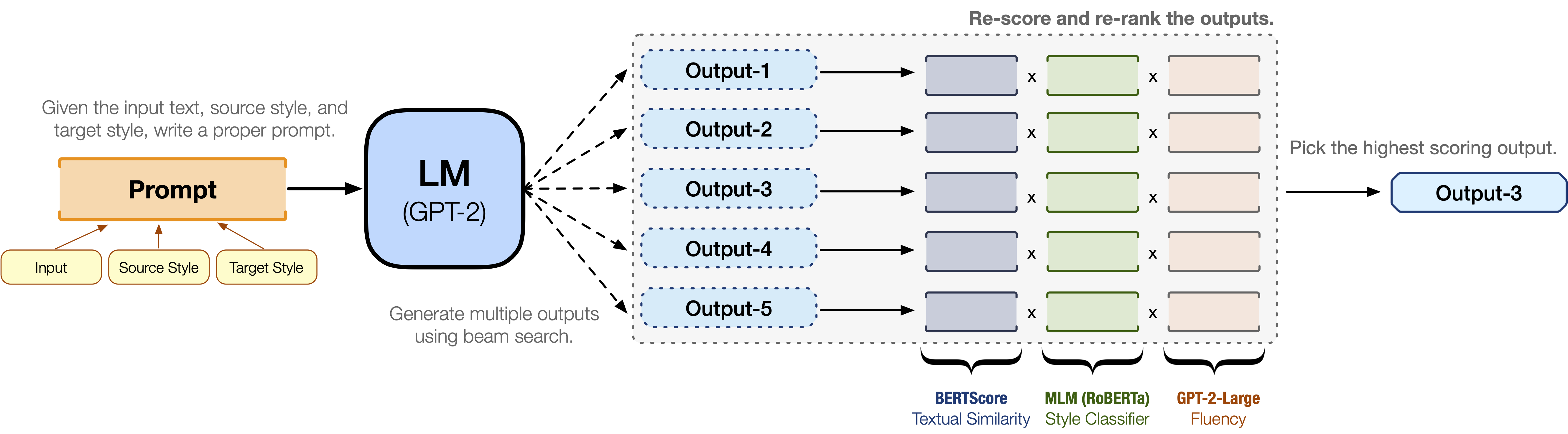
Figure (1). An illustration of our proposed Prompt-and-Rerank method. Given an input text and the style transformation, we first compose a prompt and feed it to a pretrained language model (e.g., GPT-2) to generate multiple output texts—conditioned on the prompt—using beam search. We then re-score each candidate output along three axes, namely textual similarity, style transfer strength, and fluency. We choose the candidate with the highest re-ranked score as our output.
Qualitative Examples
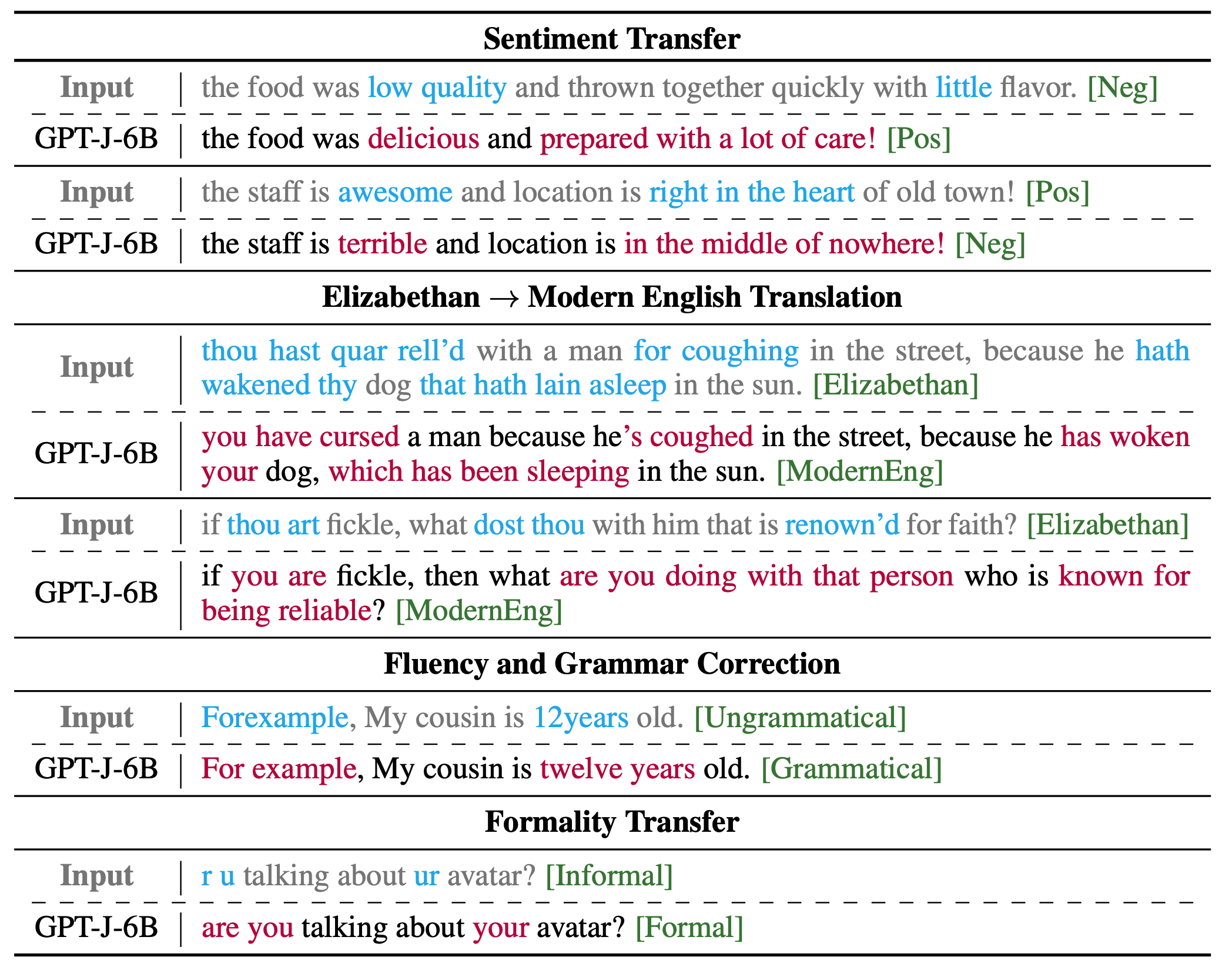
Figure (2). Qualitative examples of few-shot style transfer on the Yelp (sentiment), Shakespeare (sentiment), JFLEG (grammatic error correction), and GYAFC (formality) datasets. Coupling off-the-shelf “small” language models with our prompt-and-reranking method enables us to perform arbitrary textual style transfer without any model training or prompt-tuning. Compared to the extremely large language models (viz., ones with more than 100 billion parameters) used by Reif et al. (2022), our models obtain similar performance using almost two orders of magnitude less compute and memory.
Citation
@inproceedings{
suzgun2022promptandrerank,
title={Prompt-and-Rerank: A Method for Zero-Shot and Few-Shot Arbitrary Textual Style Transfer with Small Language Models},
author={Mirac Suzgun and Luke Melas-Kyriazi and Dan Jurafsky},
year={2022},
booktitle={arXiv}
}